7 steps of image pre-processing to improve OCR using Python
What is OCR?
Optical Character Recognition (OCR) is a course of perceiving text inside pictures and changing it into an electronic structure. These pictures could be of manually written text, printed text like records, receipts, name cards, and so forth, or even a characteristic scene photo. OCR uses two techniques together to extract text from any image. First, it must do text detection to determine where the text resides in the image. In the second technique, OCR recognizes and extracts the text using text recognition techniques. OCR is an active research area and with the introduction of deep learning, the performance of various OCR models has been increased sufficiently.

What are the application areas for OCR?
OCR has many application areas in the real world and one particularly important benefit is to minimize the human effort across various industries in our everyday life. Some of the popular application areas for OCR are the digitization of various paperwork, book scanning, reading signboards to translate into various languages, reading signboards for self-driving cars, registration number extraction from vehicle’s number plate, and handwritten recognition tasks, etc,
Why does the image pre-processing important for any OCR model’s performance?
OCR has many application areas in the real world and one particularly important benefit is to minimize the human effort across various industries in our everyday life. Some of the popular application areas for OCR are the digitization of various paperwork, book scanning, reading signboards to translate into various languages, reading signboards for self-driving cars, registration number extraction from vehicle’s number plate, and handwritten recognition tasks, etc,
We have consolidated seven useful steps for pre-processing the image before providing it to OCR for text extraction. Explain these pre-processing steps, we are going to use OpenCV and Pillow library.

Installing required software for OCR pre-processing
Install OpenCV and Pillow Library:
- Install the main module of OpenCV using pip command
- pip install OpenCV-python
- Or you can Install the full package of OpenCV using pip command
- pip install OpenCV-contrib-python
- Install Pillow library using pip command
- pip install pillow
- Import the OpenCV in the code as given below
- import cv2
Seven steps to perform image pre-processing for OCR
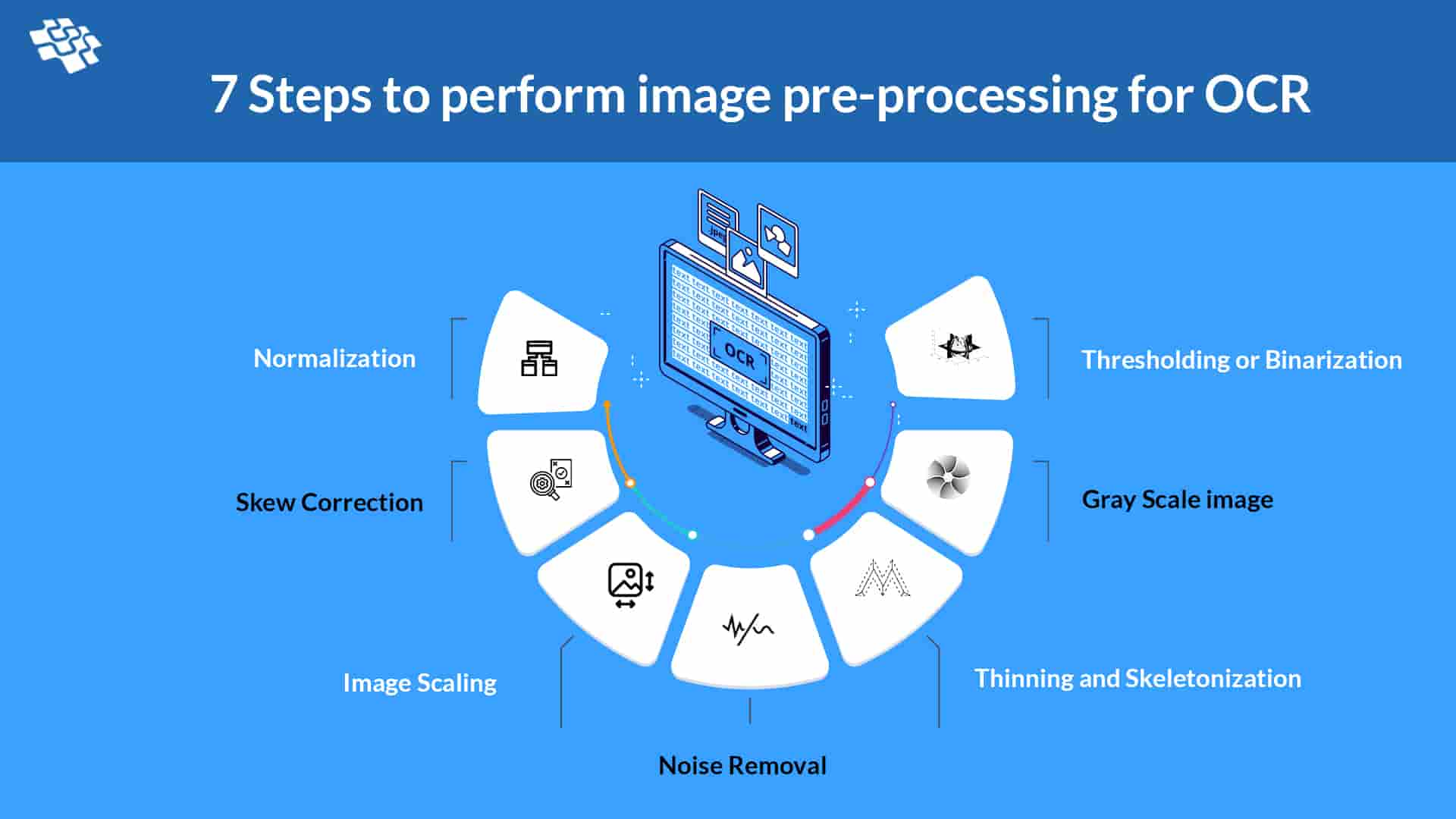
1. Normalization
This process changes the range of pixel intensity values. The purpose of performing normalization is to bring image to range that is normal to sense. OpenCV uses normalize () function for the image normalization.
norm_img = np.zeros((img.shape[0], img.shape[1])) img = cv2.normalize(img, norm_img, 0, 255, cv2.NORM_MINMAX)
2. Skew Correction
While scanning or taking a picture of any document, it is possible that the scanned or captured image might be slightly skewed sometimes. For the better performance of the OCR, it is good to determine the skewness in image and correct it.
def deskew(image): co_ords = np.column_stack(np.where(image > 0)) angle = cv2.minAreaRect(co_ords)[-1] if angle < -45: angle = -(90 + angle) else: angle = -angle (h, w) = image.shape[:2] center = (w // 2, h // 2) M = cv2.getRotationMatrix2D(center, angle, 1.0) rotated = cv2.warpAffine(image, M, (w, h), flags=cv2.INTER_CUBIC, borderMode=cv2.BORDER_REPLICATE) return rotated
3. Image Scaling
To achieve a better performance of OCR, the image should have more than 300 PPI (pixel per inch). So, if the image size is less than 300 PPI, we need to increase it. We can use the Pillow library for this.
from PIL import Image def set_image_dpi(file_path): I’m = Image.open(file_path) length_x, width_y = im.size factor = min(1, float(1024.0 / length_x)) size = int(factor * length_x), int(factor * width_y) im_resized = im.resize(size, Image.ANTIALIAS) temp_file = tempfile.NamedTemporaryFile(delete=False, suffix=’.png’) temp_filename = temp_file.name im_resized.save(temp_filename, dpi=(300, 300)) return temp_filename
4. Noise Removal
This step removes the small dots/patches which have high intensity compared to the rest of the image for smoothening of the image. OpenCV’s fast Nl Means Denoising Coloured function can do that easily.
def remove_noise(image): return cv2.fastNlMeansDenoisingColored(image, None, 10, 10, 7, 15)
5. Thinning and Skeletonization
This step is performed for the handwritten text, as different writers use different stroke widths to write. This step makes the width of strokes uniform. This can be done in OpenCV
img = cv2.imread(‘j.png’,0) kernel = np.ones((5,5),np.uint8) erosion = cv2.erode(img, kernel, iterations = 1)
6. Gray Scale image
This process converts an image from other color spaces to shades of Gray. The colour varies between complete black and complete white. OpenCV’s cvtColor() function perform this task very easily.
def get_grayscale(image): return cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
7. Thresholding or Binarization
This step converts any colored image into a binary image that contains only two colors black and white. It is done by fixing a threshold (normally half of the pixel range 0-255, i.e., 127). The pixel value having greater than the threshold is converted into a white pixel else into a black pixel. To determine the threshold value according to the image Otsu’s Binarization and Adaptive Binarization can be a better choice. In OpenCV, this can be done as given.
def thresholding(image): return cv2.threshold(image, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU) [1]
Conclusion:
OCR has a wide range of application areas in the real world and improving the performance of OCR models is necessary to avoid the mistakes in the real world. Image pre-processing reduces the error by a significant margin and helps to perform OCR better. Image pre-processing steps can be decided based on the images available for text extraction. Based on the image, some steps can be removed, and some others can be added as per requirement. The pre-processing becomes more effective when applied after having a better understanding of the input data (images) and the task to perform.
If you like the article, please let us know via your comments. If you are looking for help in NLP projects then schedule a discussion using the link or send an email to [email protected]
https://calendly.com/nextgeninvent
Follow us for more information: https://www.linkedin.com/company/nextgen-invent-corporation/
Stay In the Know
Get Latest updates and industry insights every month