Deep Learning for Computer Vision: The Ultimate Guide
The article explores the complexities and relative performances of important deep-learning architectures and applications for computer vision.

Transform Your Product With Advanced Computer Vision Services, Fostering Innovation & Efficiency
“Deep learning in computer vision has fueled great strides in a variety of problems, such as object detection, motion tracking, action recognition, human pose estimation, and semantic segmentation.”- Hindawi
Overview of Deep Learning in Computer Vision
Deep learning in computer vision, a domain within artificial intelligence and machine learning, concentrates on employing deep neural networks for tasks centered on visual perception. Its objective is to imbue machines with the ability to discern and respond to visual information. Computer vision, a fundamental component, involves training machines to interpret and understand the visual landscape. The efficacy of deep learning, particularly utilizing deep neural networks, is evident in resolving intricate computer vision challenges. This technology has demonstrated considerable success in tackling complex visual tasks, showcasing its capability to automatically learn and extract meaningful features from visual data. Deep learning in computer vision stands as a transformative force, advancing the field by providing sophisticated solutions to enhance machine understanding of the visual world.
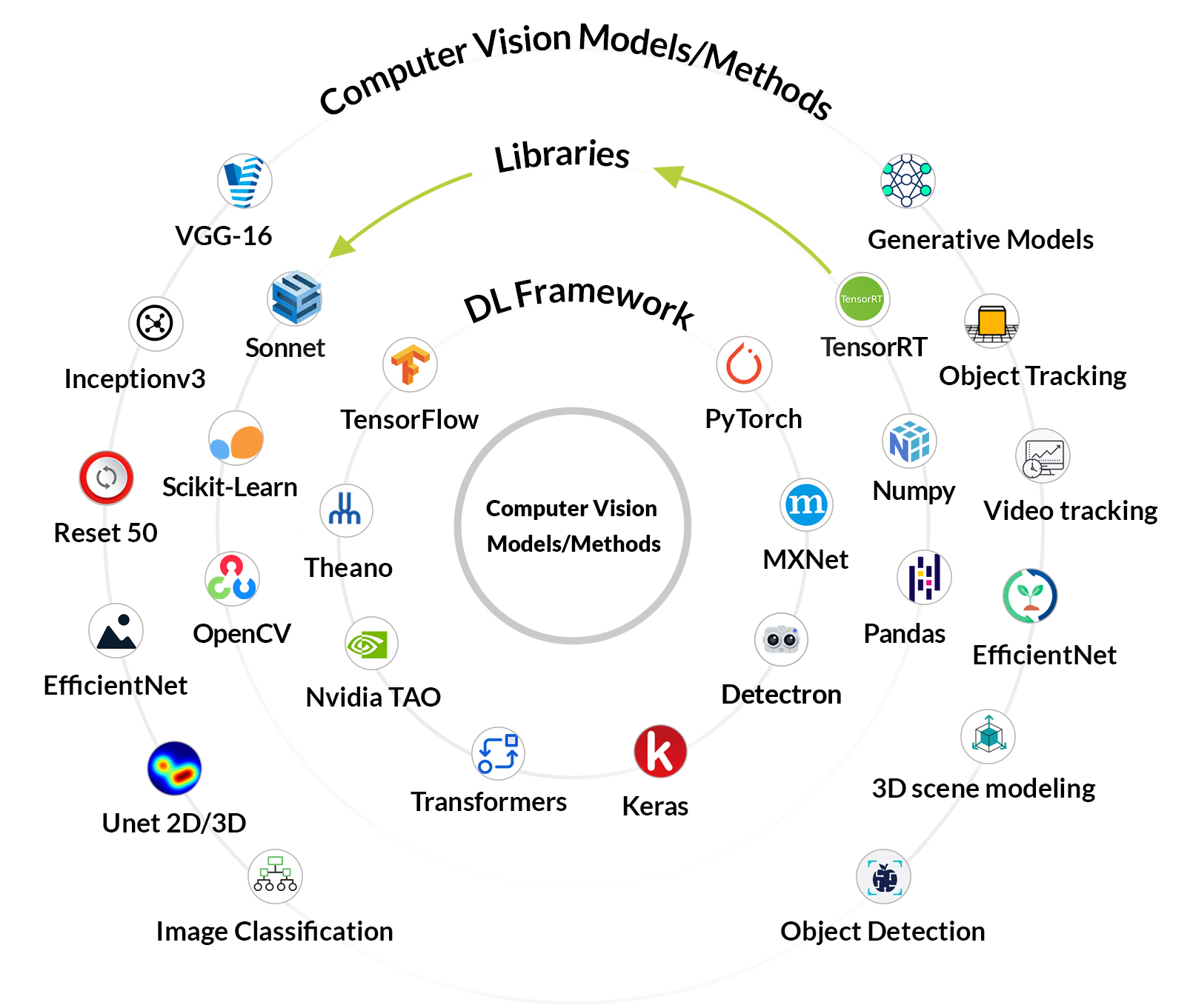
Important deep learning architectures for computer vision include:
- Convolutional Neural Networks: In computer vision deep learning, Convolutional Neural Networks (CNNs) are pivotal, employing convolutional, pooling, and fully connected layers to analyze visual data. CNNs progressively develop a nuanced understanding of input images. While pooling layers increase efficiency by lowering spatial dimensions, convolutional layers highlight picture features using trainable filters. The fully connected layers are used to merge spatial features and be fed to the target task like classification.
- Region-based Convolutional Neural Networks: CNNs use spatial information by using convolution layers. R-CNNs solve this by using CNNs on ‘proposal areas’ for object detection. Evolving versions like Fast R-CNN, quicker R-CNN, and Mask R-CNN (for pixel-level segmentation) enhance efficiency and effectiveness in addressing this limitation.
- Generative Adversarial Networks: GANs, distinct from discriminative tasks, excel in generating tasks. Comprising a discriminator and a generator, GANs play a minimax game where the networks are trained simultaneously.
Benefits of Deep Learning
Deep learning offers notable advantages over traditional machine learning. Key benefits include automatic feature extraction and hierarchical learning, enabling more effective analysis and understanding of visual data:
- Automatic Feature Learning: Deep learning in computer vision eliminates the need for manual feature design as algorithms autonomously learn from data. This is particularly advantageous in tasks like image recognition, where intricate features are challenging to articulate. The ability to automatically extract relevant features enhances the efficiency and accuracy of visual data analysis.
- Predictive Modeling: Deep learning in computer vision empowers organizations to predict future trends and events, providing valuable insights for strategic decision-making and future planning. Predictive modelling is more about sequential time-series data which seldom uses CNNs. Leveraging advanced algorithms, this technology enhances forecasting capabilities, enabling businesses to proactively address challenges and capitalize on emerging opportunities in diverse domains.
- Handling Large & Complex Data: Deep learning systems proficiently handle both organized and unstructured data types, such as images, text, and audio. Their versatility in processing diverse data formats makes them a robust solution for extracting meaningful insights and patterns across various domains, contributing to advancements in image analysis, natural language processing, and audio recognition.
Deep Learning for Computer Vision: Uses and Applications
The advancement of deep learning technology makes it possible to create complex and accurate computer vision models. Applications for computer vision and deep learning are becoming more useful together. A range of applications demonstrate how deep learning can be enhanced for computer vision:
 1. Semantic Segmentation
1. Semantic Segmentation
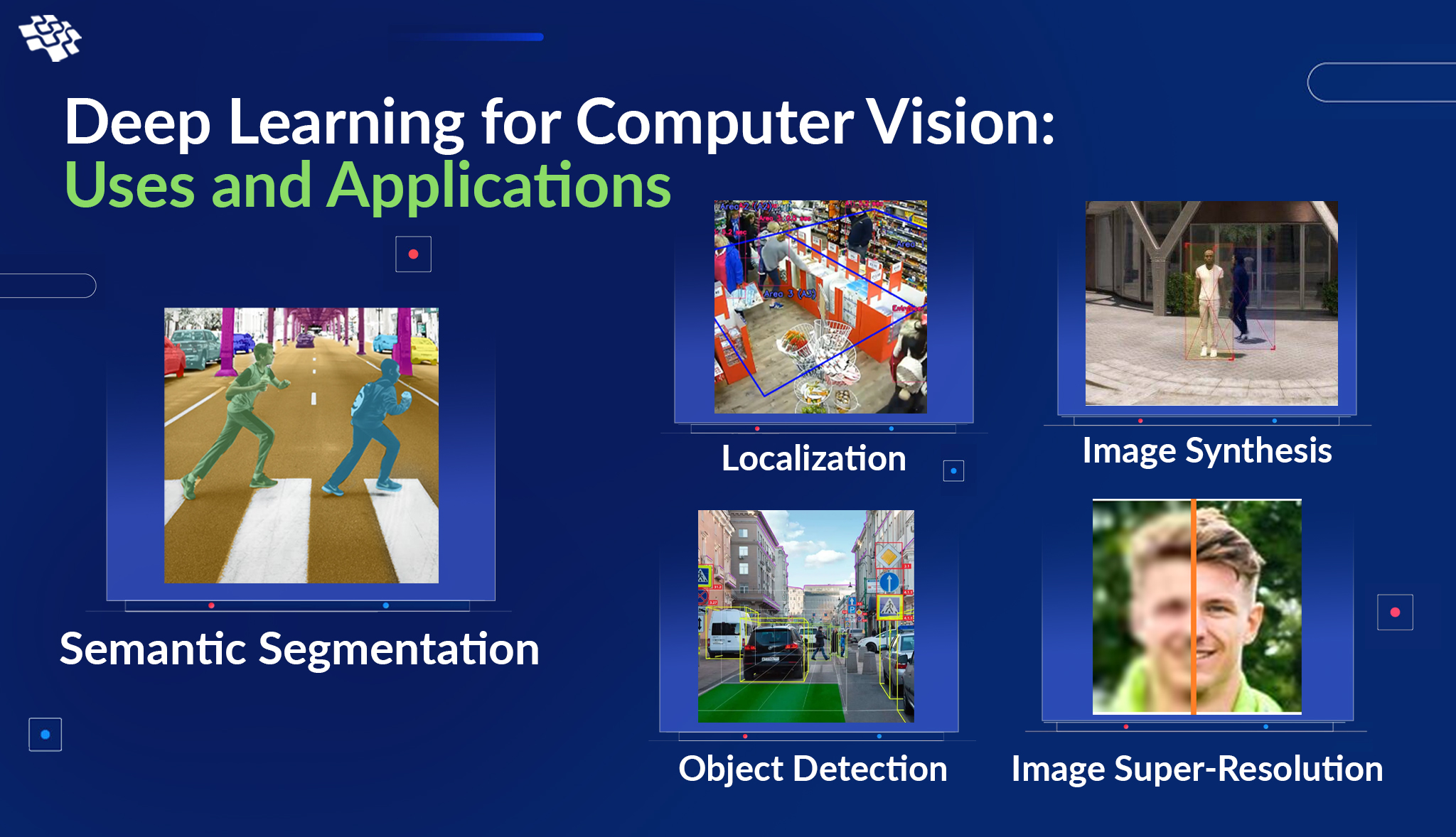 1. Semantic Segmentation
1. Semantic SegmentationIn deep learning for computer vision, semantic segmentation stands as a technique akin to object detection but with a nuanced focus on delineating specific pixels associated with an object. This approach eliminates the need for bounding boxes, offering a more precise specification of image objects. Techniques such as U-Nets or fully convolutional networks (FCN) are commonly employed for semantic segmentation, providing the capacity for detailed pixel-level understanding. The significance of semantic segmentation is particularly pronounced in applications like autonomous vehicle training, where discerning individual pixels contributes to more accurate scene interpretation. In essence, semantic segmentation enhances the interpretability of visual data, playing a pivotal role in advancing computer vision tasks with a focus on detailed object analysis.
2. Object Detection
In deep learning in computer vision, two prevalent object detection methods exist. The first employs a Region Proposal Network (RPN) to propose potential regions containing significant objects, followed by a neural classification architecture like Fast RCNN for further analysis. Although accurate, these methods can be slow. In response, one-step object detection architectures like SSD and RetinaNet have emerged, aiming for real-time detection. These architectures integrate detection and classification through bounding box regression, streamlining the process. SSD and RetinaNet optimize speed by representing bounding boxes with minimal coordinates, allowing faster processing and seamless integration of detection and classification stages. This evolution in object detection techniques within deep learning enhances both accuracy and efficiency, addressing the demand for real-time applications.
3. Localization
A crucial step in deep learning for computer vision is image localization, which marks the location of an object in an image with bounding boxes. Object detection further categorizes identified objects, with CNNs such as AlexNet, Fast RCNN, and Faster RCNN forming the backbone of this procedure. Object detection and localization are particularly powerful in discerning multiple objects within complex scenes. Beyond mere identification, this information holds substantial utility in applications like deciphering medical diagnostic imaging. The amalgamation of deep learning techniques, through networks like CNN, not only enhances the accuracy of localization and detection tasks but also opens doors for transformative applications in fields where precise object localization and identification are paramount, such as in advanced medical imaging analysis.
4. Image Synthesis
Deep learning in computer vision has greatly advanced image synthesis, a process where new, realistic images are generated by the model. Generative Adversarial Networks (GANs) play a pivotal role in this domain, creating images that are indistinguishable from real ones. Among the many uses for image synthesis are virtual try-ons in the fashion industry, data augmentation for model training, and creating lifelike settings for simulations and video games. Another use for style transfer is to change an image’s visual style by smoothly integrating artistic components. These methods make use of deep neural networks to discover intricate links and patterns in data, which makes it possible to produce photos that are both realistic-looking and of excellent quality. The advancement of picture synthesis skills in deep learning frameworks creates new opportunities for imaginative applications and lifelike simulations in diverse industries.
5. Image Super-Resolution
Image super-resolution is a significant application within deep learning in computer vision, aiming to enhance the resolution and quality of low-resolution images. Deep neural networks, Deep neural networks, particularly Generative Adversarial Networks (GANs), have demonstrated remarkable success in this domain. Models like SRGAN (Super-Resolution Generative Adversarial Network) utilize adversarial training to generate high-resolution images with finer details. This technology finds applications in various fields, from improving the clarity of medical imaging to enhancing the quality of surveillance footage. By training on large datasets, these models learn intricate features and patterns, enabling them to reconstruct high-resolution versions from lower-resolution inputs. Image super-resolution exemplifies how deep learning techniques can significantly impact visual data enhancement, providing sharper and more detailed images for a range of practical applications in diverse industries.
Ethical Concerns in Computer Vision
- Bias & Discrimination: Computer vision, if trained on biased datasets, can perpetuate and magnify societal biases, leading to discriminatory outcomes in gender, race, and other characteristics. Addressing these biases is crucial to ensure equity and prevent the exacerbation of existing societal disparities. It underscores the importance of developing and refining computer vision systems with a focus on fairness and unbiased representation of training data.
- Security & Surveillance Concerns: While computer vision enhances surveillance and security, its improper application raises ethical concerns like mass surveillance and unauthorized access to private data, posing cybersecurity risks. Striking a balance between personal privacy and public safety is crucial to mitigate these concerns, ensuring responsible deployment and usage of computer vision technology in ways that respect individual rights and safeguard against potential harm.
- Invasion of Privacy: Widespread use of computer vision, particularly facial recognition in surveillance systems, raises privacy concerns. Unauthorized tracking and monitoring infringe on privacy rights, prompting ethical concerns regarding consent and the collection of personal data. This invasion of private spaces necessitates careful consideration to ensure the responsible and ethical deployment of computer vision technologies, respecting individual privacy and rights.
Deep Learning for Computer Vision with NextGen Invent
Delving into the world of deep learning for computer vision has unraveled the immense potential and transformative impact on various industries. From image classification to generative visual tasks, the evolution of techniques like CNNs and GANs has revolutionized visual data analysis. As we navigate the intricate landscape of computer vision, NextGen Invent stands at the forefront, offering cutting-edge Computer vision development services. Our expertise encompasses leveraging deep learning in computer vision, ensuring innovative solutions that meet diverse industry needs. Harness the power of advanced algorithms and neural networks with NextGen Invent’s tailored services, driving efficiency and accuracy in your computer vision applications. Experience the future of visual data processing with our expert team.
Contact us today for bespoke computer vision solutions that propel your business into the next generation. Your vision, powered by deep learning, is our commitment.

“Deep Learning for Computer Vision acts as a powerful lens, decoding intricate patterns within pixels. Neural networks enable machines to grasp visual nuances, enhancing the ability to perceive, interpret, and innovate—an unfolding era where artificial intelligence truly comprehends the language of images.”
Tejalal Choudhary
Data Scientist
Related Blogs
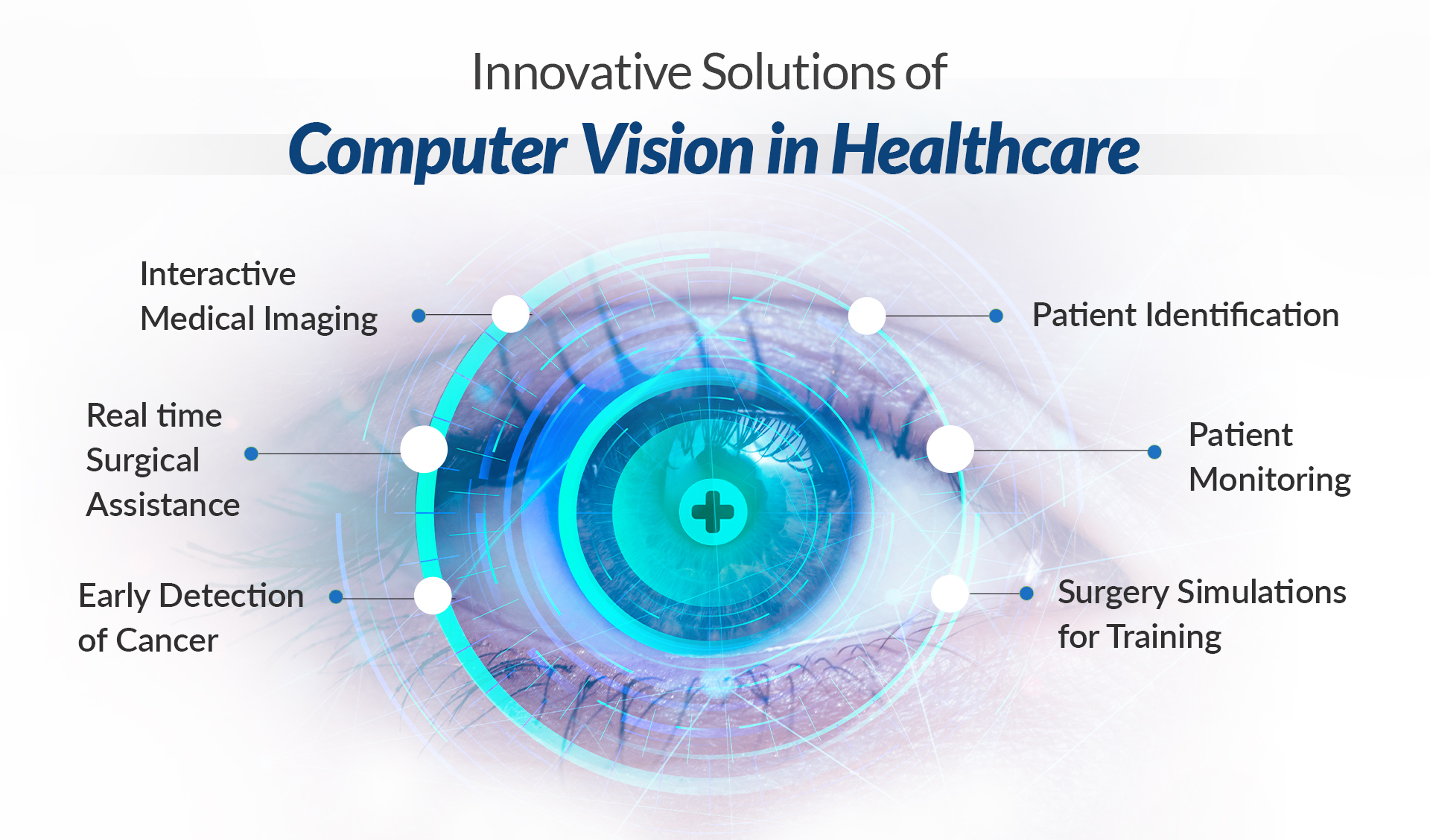
Computer Vision in Healthcare: Transformation is Here
Within healthcare, the efforts of medical professionals play a pivotal role and have a direct impact on patients’ well-being. Advanced computer vision in healthcare technologies, particularly in object recognition, empowers physicians with an unmatched ability to focus and keenly observe critical details.
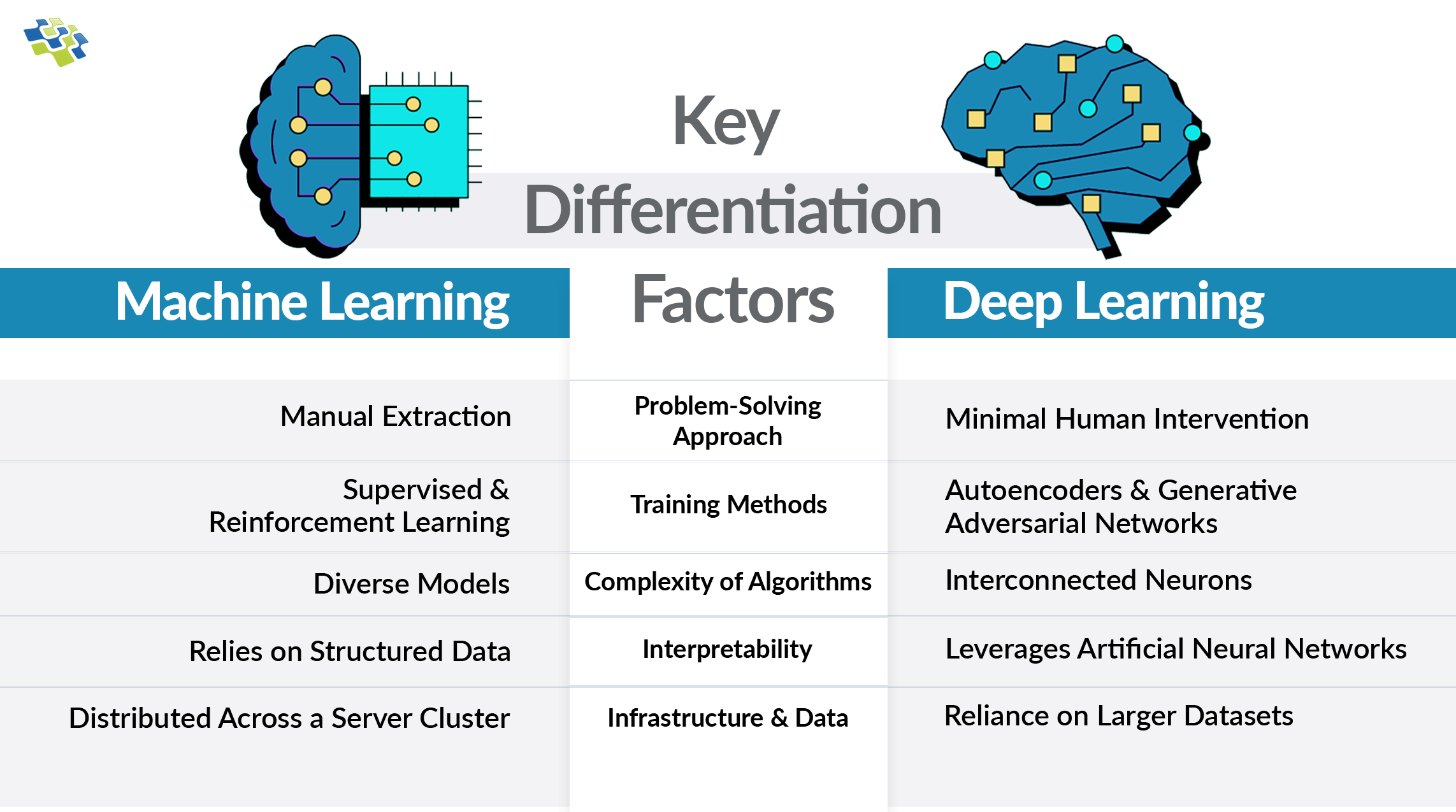
The Ultimate Comparison of Machine Learning vs Deep Learning
Artificial intelligence (AI) can seem overwhelming with its rapid advancements, but at its core, two fundamental ideas drive much of its progress: Machine Learning vs Deep Learning. These concepts have found extensive applications across various domains.

How Computer Vision is Revolutionizing AI Inventory Management?
AI inventory management is revolutionizing large-scale corporate operations by enhancing efficiency and accuracy. Through precise product location tracking, this innovative technology optimizes processing and stocking, ensuring seamless movements with the right force.
Stay In the Know
Get Latest updates and industry insights every month.